
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- PointNet++
- logarithm mapping
- point cloud
- deformable KPConv
- 경제 공부
- PointNet
- TURTLEBOT3
- 백준 1253번
- exponential mapping
- Docker
- OpenCV
- ros2
- SLAMKR
- 제 6장
- visual slam
- 부자 아빠 가난한 아빠
- 2 포인터 알고리즘
- C++
- Raspberry Pi
- 코딩 테스트
- 입문 Visual SLAM
- KPConv
- OpenCV 모듈
- IMAGE
- 논문 리뷰
- rigid KPConv
- 코딩테스트 공부
- Slam
- FeatureMatching
- 코딩테스트
- Today
- Total
꿈꾸는 개발자
PointNet 논문 리뷰 본문
PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation
논문을 보기 앞서 Point Cloud 데이터에 대한 특성을 알 필요가 있다.
Point Cloud 데이터는 unordered(순서가 정해져있지 않음)하고 강체 운동에 불변하다.
이는 각 점들의 입력 순서를 변경하더라도 3D 객체나 형태가 변하지 않고 Point Cloud에 Transformation을 적용해도 3D 객체나 형태가 변하지 않는다는 것을 의미한다.
이러한 Point Cloud 특성을 반영해 논문에서는 permutation invariance 라는 단어를 사용하는데, 이는 Point Cloud의 점들이 어떤 순서로 입력되든지 간에 일관된 결과를 도출한다는 의미를 나타낸다.
1. Introduction
전형적인 CNN 아키텍쳐는 weight sharing과 kernel optimization을 수행하기 위해 정형적인 입력 데이터 형식이 필요(3D voxels)
그러나, Point Cloud 혹은 mesh 는 정형적인 형식이 아니기 때문에 대부분의 연구자들은 Point Cloud를 정형적인 데이터 형식(3D voxel girds or collections of images)으로 바꿔 Deep Learning 아키텍쳐에 입력으로 전달했지만 이러한 데이터 변형은 불필요하게 방대하게 만든다는 단점이 있음
이를 해결하기 위해 Point Cloud를 그대로 입력으로 넣을 수 있는 Deep learning 아키텍쳐인 PointNet을 제안
PointNet의 입력으로는 Point Cloud의 세 좌표(x, y, z)를 받고, 추가적으로 normal 혹은 local or global feature가 계산됨으로써 추가될 수 있게 구성

PointNet의 중요한 접근법은 single symmetric function인 max pooling을 사용한다는 것
Point Cloud의 중요한 정보들을 갖고 있는 점들을 선택해 최종 FC layer에서 이러한 최적의 값들로 shape classification이나 shape segmentation을 진행
또한, 입력에 rigid, affine transformation을 적용할 수 있기 때문에 spatial transformer network를 추가할 수 있고, 이를 통해 PointNet이 Point Cloud를 처리하기 전에 정규화(canonicalize) 하면서 결과를 향상시킬 수도 있음
2. Related Work
Skip
3. Problem Statement
PointNet은 object classification, part region segmentation에서 다른 출력으로 모델을 구성

PointNet의 구조 중 파란색 부분은 Classification 구조, 노란색 부분은 Segmentation 구조를 나타낸다.
4. Deep Learning on Point Sets
4.1 Point Sets의 주요 특징
- Unordered : 앞서 글의 맨 처음에서 언급
- Interaction properties : 인근 위치의 포인트끼리는 유사한 정보를 가지고 있음
- Invariance under transformation : Transformation이 적용되더라도 3D 객체 자체가 변하지 않음
4.2 PointNet Architecture
PointNet의 구조에서 Key module은 총 3가지로 나눌 수 있음
- Max pooling layer
- 특징 정보의 응집(Symmetric function to aggregate information from all the points)
- Combination structure
- 지역적 or 전역적 정보를 조합
- two joint alignment networks(align both input points and point features)
- 입력 포인트와 포인트 특징들을 정렬
Symmetry Function for Unordered Input - Max pooling을 왜 사용하게 되었는지, Unordered 한 입력에 대해 어떻게 다루었는지에 대한 내용을 서술한 부분
총 3가지 전략이 있었음을 제시를 했고, 이에 대한 결과를 보여줌

- sort input into a canonical order
- 정렬을 할 수 있다고 가정할 때, 고차원 공간에서 1차원 공간으로의 매핑은 가능하지만 point에 perturbation(섭동)이 추가될 경우 고차원 공간에서 1차원 공간으로 매핑한 점이 일대일 대응을 보장할 수 없음으로 이 전략은 불가능
- treat the input as a sequence to train an RNN, but augment the training data by all kinds of permutations
- 짧은 길이의 입력에 대해서는 상대적으로 강건한 결과를 보였으나, 매우 많은 양의 입력이 되면 좋지 않은 결과를 보였기에 이 전략도 불가능
- use a simple symmetric function to aggregate the information from each point
- 최종적으로 symmetric function으로 point set에 적용함으로써 근사화 한 후 입력으로 사용했을 때 가장 좋은 성능을 보였기에 이 전략을 사용
Local and Gloabl Information Aggregation - Combination Structure에 대한 세부 설명

Segmentation Network에서 global feature와 local feature를 함께 concatenate를 함으로써 각 포인트 특징들이 local and global 정보를 함께 가질 수 있게 되었음을 보여줌
이를 통해, shape part segmentation과 scene segmentation 부분에서 우수한 성능을 보임
Joint Alignment Network - two joint alignment networks 에 대한 세부 설명
Point Cloud의 성질 중 transformation이 적용되더라도 invariant 해야하는 특성 상 이를 적용하기 위해 이전 해결책으로 특징 추출 전에 모든 입력을 canonical space로 정렬하는 방법이 있었지만, 더 간단한 방법으로 제안
T-Net 이라는 mini-network를 추가해 affine matrix 를 예측하고 입력 포인트들에 transformation을 적용하는 방법으로 진행
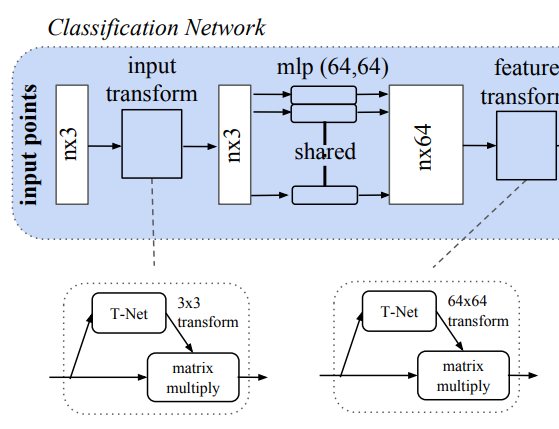
T-Net을 이용해 transformation matrix를 추정할 때 feature space 에서의 추정은 spatial transform matrix 보다 더 고차원 형태로 optimization에 어려움이 증가한다는 단점이 존재
regularization term을 추가함으로써 orthogonal matrix로 변경해 최적화를 더 쉽게 만들어줬음
$ L_{reg} = || I - AA^{T}||^{2}_{F} $
이때, A 는 feature alignment matrix로 T-Net을 통해 예측된 matrix이다.
5. Experiment
3D Object Classification

기존 방법론의 경우 Point Cloud를 image로 변환하거나 여러 view 를 사용해서 전처리를 진행한 후 진행했지만, PointNet의 경우 input을 그대로 사용했음에도 성능이 우수한 것을 확인할 수 있음
Supplementary

Point Cloud에 Transformation을 적용했음에도 적절한 Correspondence를 찾는 것을 확인할 수 있음


'논문 리뷰' 카테고리의 다른 글
| KPConv : Flexible and Deformable Convolution for Point Clouds 논문 리뷰 (1) | 2024.01.11 |
|---|---|
| Dynamic Graph CNN for Learning on Point Clouds 논문 리뷰 (1) | 2024.01.10 |
| PointNet++ 논문 리뷰 (0) | 2024.01.09 |


